 超算云
超算云 AI智算云
AI智算云专注Coding与长程任务,智谱GLM-5.2接入北京超算MaaS平台

北京超算MaaS平台已上线智谱新一代开源旗舰模型 GLM-5.2。
海量算力,极致性能。立即体验,一键开启您的普惠智算之旅!⬇️
https://ai.blsc.cn/#/lms/model
以下内容来自智谱公众号,点击阅读原文
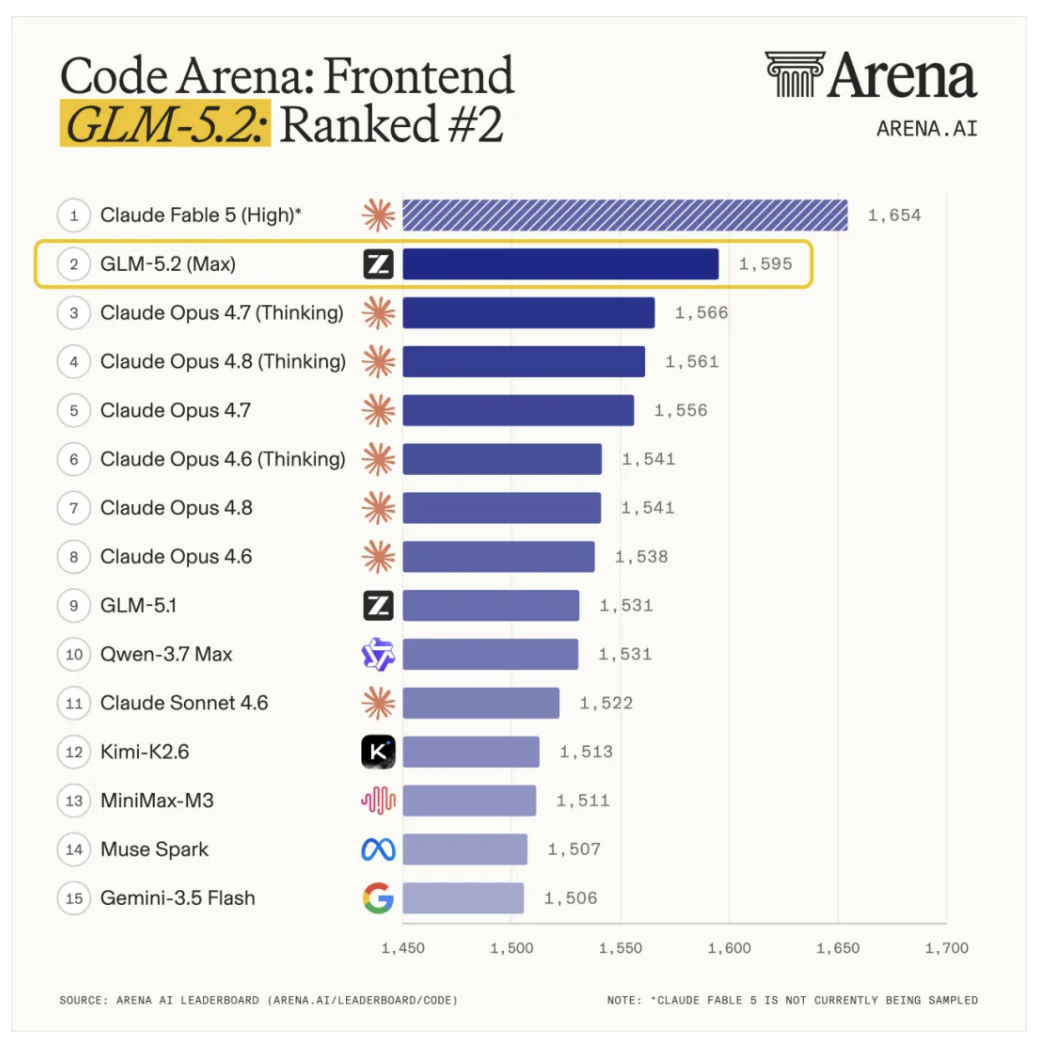
在全球百万用户参与盲测的前端开发评估系统Code Arena 上,GLM-5.2取得全球可用模型第一的表现。
一、1M上下文与长程任务
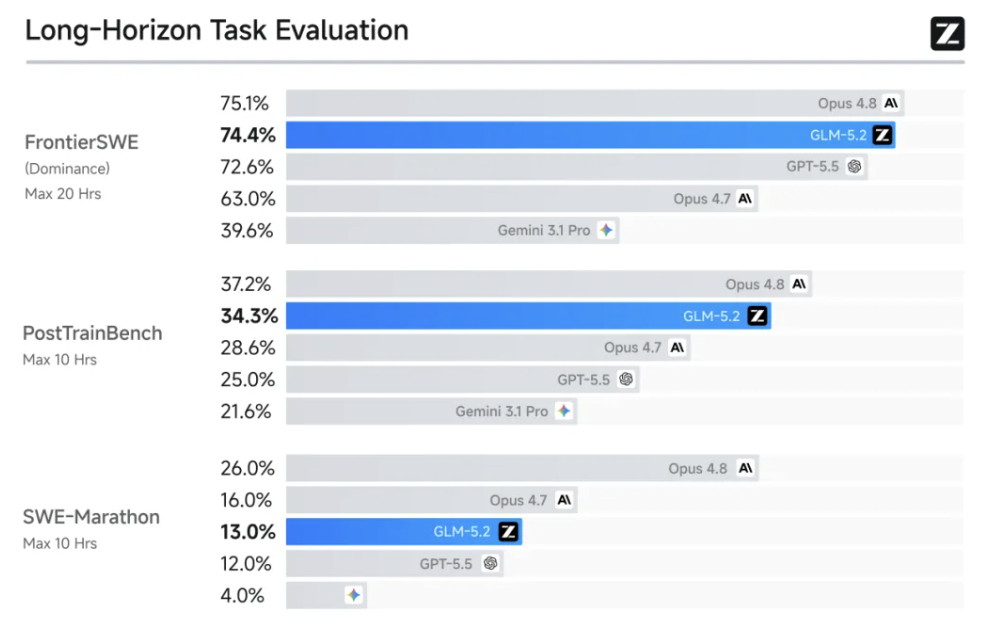
1M上下文构成GLM-5.2的长程交付能力,在FrontierSWE、SWE-Marathon、PostTrainBench等多个长程任务基准上,GLM-5.2的表现介于Claude Opus 4.7与4.8之间,是排名最高的开源模型。在FrontierSWE(一个测试AI是否能够像顶级软件工程师和研究员一样,在数小时到数十小时尺度上完成复杂技术项目的测试集)上仅比Opus 4.8低1%,超过GPT-5.5(1%)和Opus 4.7(11%);不过在SWE-Marathon(一个考察Agent能否自主完成超长周期的软件工程工作的测试集)上确实还需要进一步提高,低于Opus 4.8不少(13%)。
在实际体验中,GLM-5.2自主完成开发、联调、测试到打包上线,最终交付一个覆盖Web、移动端与小程序的多端应用。这样一条完整链路累计处理88万以上的tokens,几乎用满1M上下文窗口。过去,这样的大型工程需要一支团队协作数周,GLM-5.2能在一次连续的长程任务中跑完。
二、Coding体感
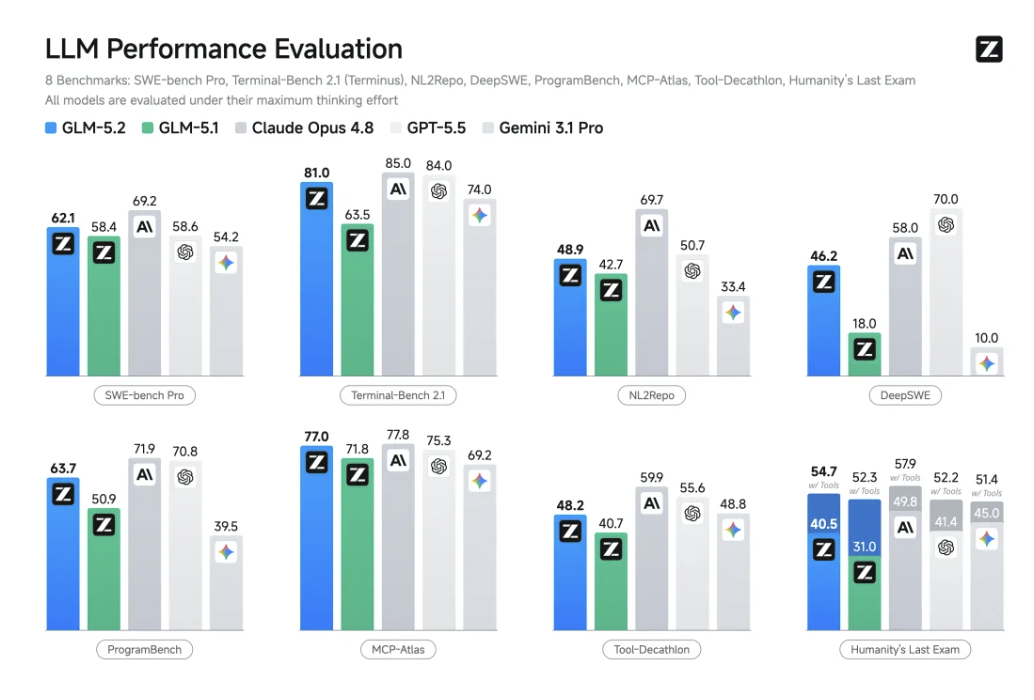
GLM-5.2在前端、后端、长程任务等开发场景下的成功率相比前一代GLM-5.1都有长足提升,复杂系统工程与深度调试更稳。在主流编程基准上,GLM-5.2保持开源SOTA,与Claude Opus 4.8处于可比区间。例如在Terminal-Bench 2.1上(评测AI Agent通过命令行操作一台计算机的数据集),GLM-5.2比Opus 4.8低4%,相比GLM-5.1提升了17.5%;在MCP-Atlas上(工具使用tool-use评测的数据集),GLM-5.2仅比Opus 4.8低0.8%。
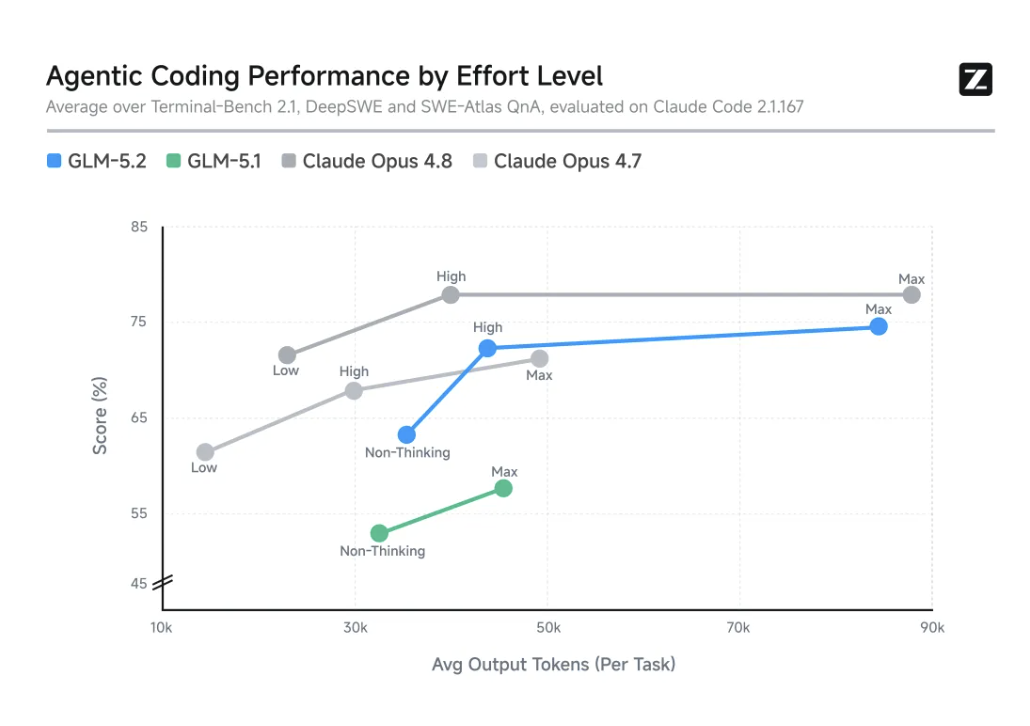
GLM-5.2还引入了effort level(思考档位)控制,可以在能力、速度、成本之间做出平衡。在相近的token预算下,GLM-5.2的Coding能力大致位于Claude Opus 4.7与Claude Opus 4.8之间。
三、极致Infra优化
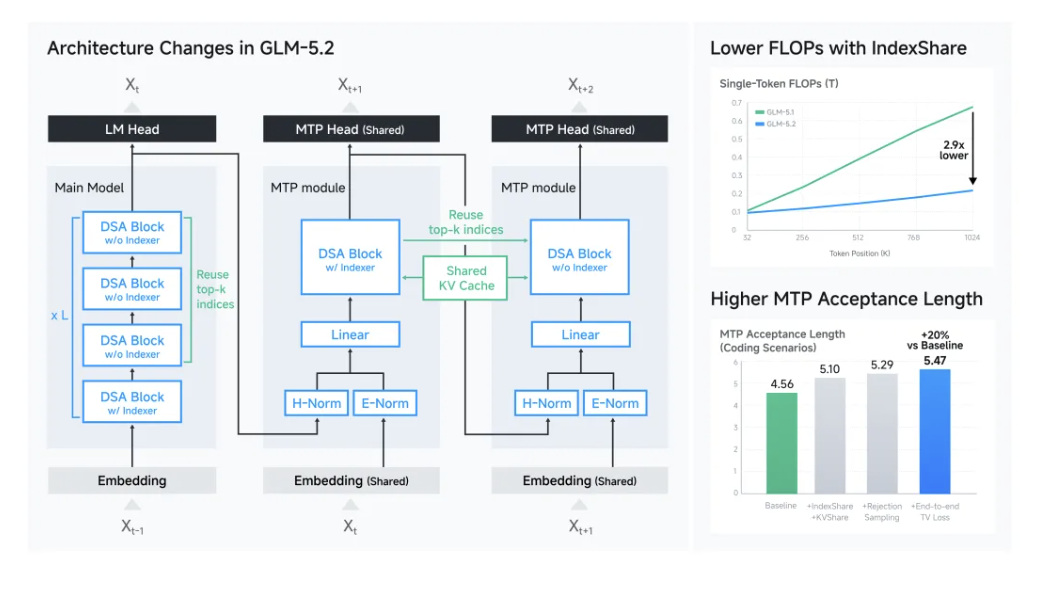
GLM-5.2的进步来自模型架构、推理系统和训练基础设施的协同设计。智谱提出IndexShare,在每四层稀疏注意力层之间复用同一个索引器(indexer),在1M上下文长度下,将单位token的FLOPs降低至2.9倍。此外改进了用于投机解码(speculative decoding)的 MTP 层,将接受长度(acceptance length)最多提升 20%。训练侧则依赖自研Slime框架支撑大规模Agentic RL和OPD训练。
随着GLM系列的持续迭代与调用量的快速增长,线上服务的稳定性与效率愈发关键。GLM-5.2的线上推理依托多个国产算力平台,已在Day 0完成与华为昇腾、平头哥、摩尔线程、寒武纪、昆仑芯、沐曦、海光、壁仞、天数智芯等国产算力平台的推理适配,在国产芯片集群上实现高吞吐、低延迟、大并发的稳定运行。预计下半年昇腾 950 超节点上市后,也将成为GLM-5.2强劲的算力底座。
四、面向开发者与知识工作者
凭借扎实的1M上下文与稳定的长程任务能力,GLM-5.2能长时间自主推进更复杂、更长链路的任务,锁定高价值场景,改变开发者与知识工作者的工作方式。
开发者:
GLM-5.2在大型重构工程上表现出色。在开发者的Moonshot实验中,它用Rust从零再造了送人类登月的计算机——阿波罗11号制导计算机(AGC):把约4,600行的定点CPU逐比特移植为Rust,再让当年65,000行、一字未改的登月飞控程序在上面原样起飞。整个过程由Agent全自主走完,直到复现那个差点中止登月的1202报警。
知识工作者:
通过智谱的Agent产品AutoClaw,GLM-5.2的1M上下文与长程任务能力可服务于设计、法务等专业场景,例如从需求一次性生成数十个原型页面,并自主持续迭代和微调,在长上下文中保持品牌规范与一致性。






