 超算云
超算云 AI智算云
AI智算云实测:那个让VASP“内存爆炸”的40原子算例,后来怎么样了?
一群与材料“较劲”的人
某双一流高校前沿材料计算课题组,长期从事新型量子材料的发现与性质研究——拓扑材料、多铁材料、关联电子体系都在他们的视野中。
他们的研究方法很清晰:VASP + 高通量第一性原理计算 + 系统化任务流程。

曾经最头疼的事:高通量变“低效率”
课题组负责人坦言:“我们不是算一个两个体系,而是成百上千个参数组合同时推进。”
过去,他们几乎每天都要面对海量任务的队列拥堵、资源调度僵化,以及任务失败后反复的人工排查与重提。明明想高通量,现实却是“低效率+高维护”。怎么办?
短期3-5万核并发、按需波动、时间紧张、预算有限,层层加码让可选资源范围越来越小。
转机:M9海量核心 + 性能调优,
攻克大规模并行难题
课题组把目光投向了北京超算的M9分区——国内规模领先的AMD都灵架构集群,18万核心。
但一上来就遇到了棘手问题:他们的VASP计算“跑不动”!
负责对接的北京超算技术工程师第一时间介入排查。

作业异常信息摘要
通过使用自研应用性能特征分析工具,发现问题:运行的任务量并行规模远大于以往场景,算力类型多,工具监测到一些原子数较多的算例(达40个原子以上),计算到最后阶段内存占用会突然飙升,在频繁报“内存溢出”,导致作业崩溃。
工程师没有走捷径。他们做了三件事:
编译器深度调优:对比了oneAPI、不同版本的intelmpi、openmpi+aocc等多种组合,最终锁定intelmpi 17版本编译的VASP——内存使用量最低,稳定性最好,完美适配M9的大规模并行架构。
动态调整作业配比:将单作业从64核调整到96核,在不显著增加预算的前提下,为每个任务争取到更充裕的计算资源。
海量资源弹性协调:依托M9的18万核心池,根据课题组的任务进度,按需灵活调配3~5万核资源,既满足峰值需求,又节约总体成本。
效果如何?
最终,工程师随机测试的10余组算例全部成功运行完成。
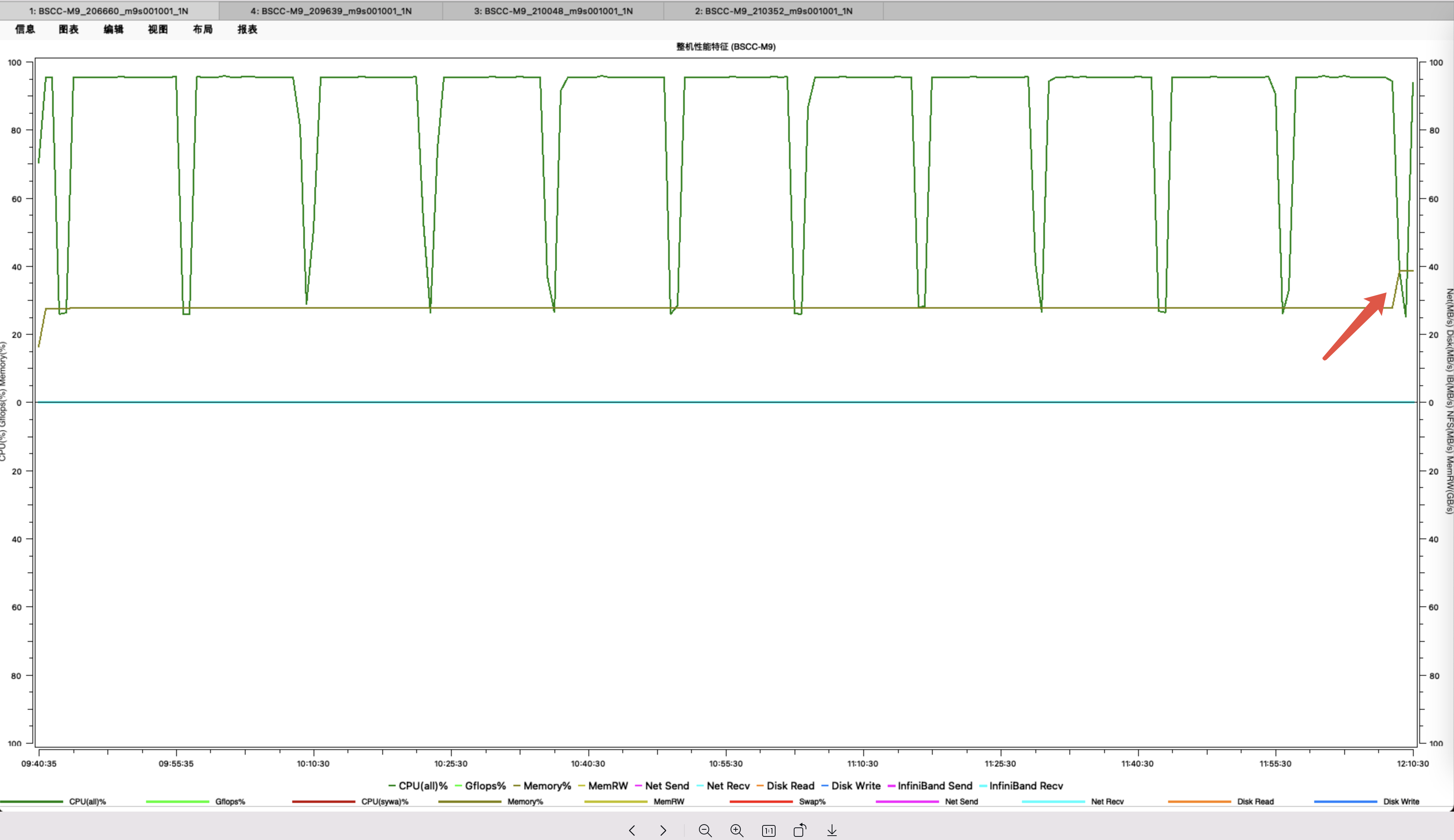
采集作业性能特征监控内存调用
如今:吞吐量翻倍,研究周期缩短
问题不在“算得慢”,而在“算不稳”。稳住,才有高通量。
现在,整个课题组的计算节奏彻底变了。一位团队成员感慨:“以前感觉每天都在‘救火’,现在终于可以专注在物理分析本身了。”
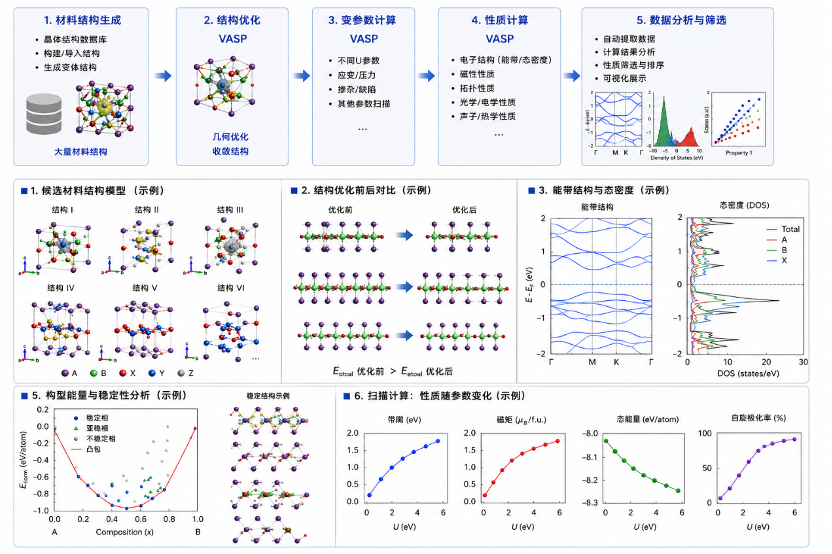
材料计算全流程示意图
客户心声:“稳定,比什么都重要”
M9凭什么?
北京超算 M9 分区,正是为这类高通量、高并发、高连续性的计算任务而设计:
• 国内规模领先的 AMD 都灵架构 CPU 集群
总核心数高达 18万核,轻松承载成百上千个任务并行;
• 极致单精度浮点性能
高达 22 TFlops,在当前CPU资源中堪称“算力王者”;
• 核存比可调 + 大内存设计
针对VASP、CP2K、QE等材料软件深度优化,支持大原子体系稳定运行;
• 统一环境 + 专业工程师陪跑
编译器、库环境统一配置,遇到问题有专业人员快速定位,不再孤军奋战。
北京超算M9分区,让高通量材料计算,从“能不能跑”变成“跑得稳、跑得快、跑得省心”。如果您也正被大规模计算任务的稳定性、排队、失败重算所困扰,欢迎联系我们,体验M9分区带来的“极致性能”。







