 超算云
超算云 AI智算云
AI智算云北京超算MaaS平台上线MiniMax M2.5,刷新行业SOTA !

2月13日,稀宇科技发布了其最新一代旗舰模型MiniMax M2.5,北京超算MaaS平台当天即完成模型部署,现已开放体验,点击链接即可调用:
https://ai.blsc.cn/#/lms/model
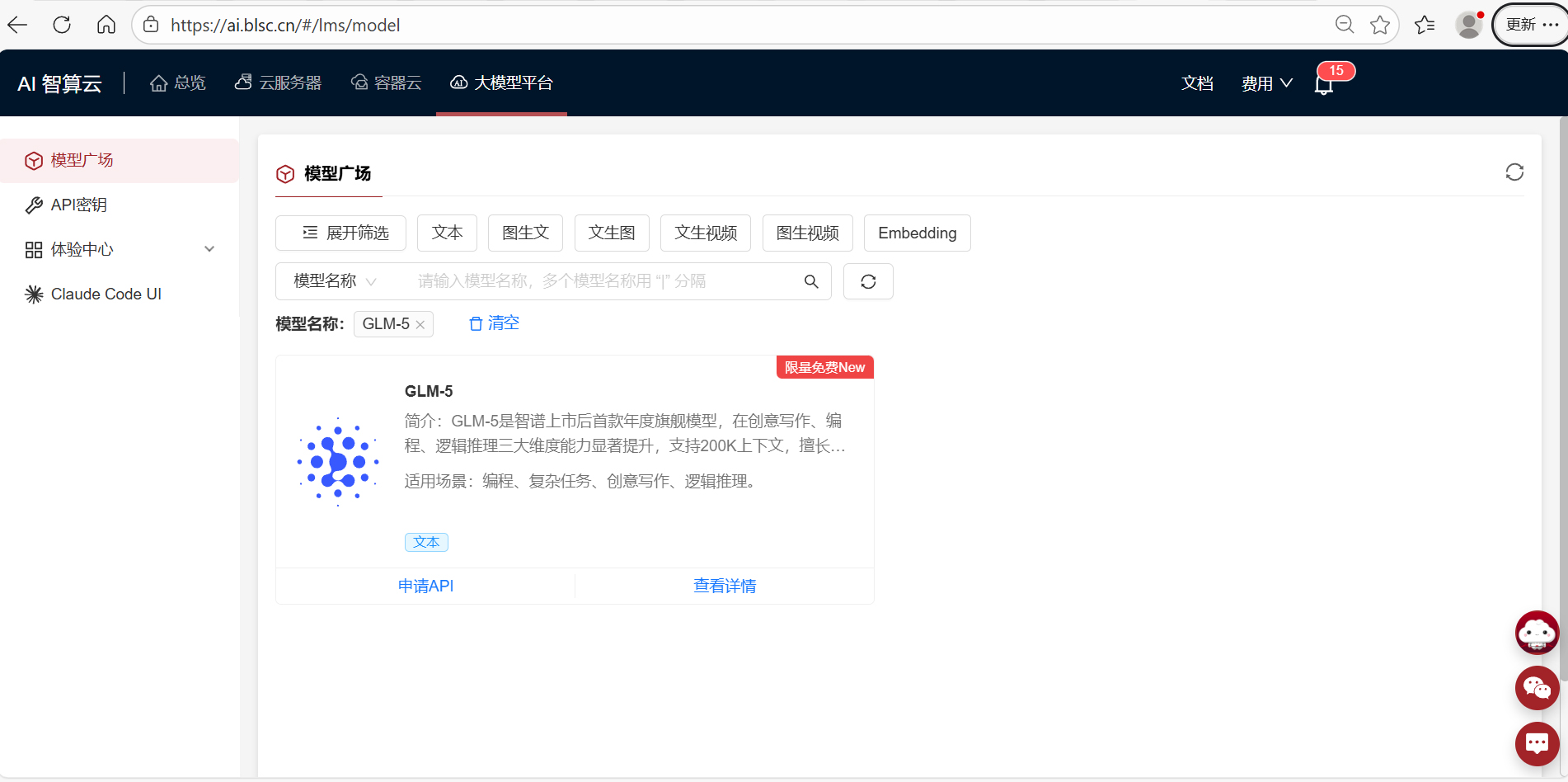
M2.5在编程、工具调用、搜索及办公等生产力场景中均展现出了显著的性能提升。
· M2.5 在编程、工具调用和搜索、办公等生产力场景都达到或者刷新了行业的 SOTA,比如 SWE-Bench Verified (80.2%),Multi-SWE-Bench (51.3%),BrowseComp (76.3%);
· M2.5 优化了模型对复杂任务的拆解能力和思考过程中 token 的消耗,使其能更快地完成复杂的 Agentic 任务。在 SWE-Bench Verified 的测试中,M2.5 比上一个版本 M2.1 完成任务的速度快了 37%;
· M2.5 让无限运行复杂 Agent 在经济上可行。在每秒输出 100 token 的情况下,M2.5 连续工作一小时只需花费 1 美金;而在每秒输出 50 个 token 的情况下,只需要 0.3 美金。
MiniMax 内部已率先受益于 M2.5 的模型能力。在 MiniMax 内部真实业务场景中,整体任务的 30% 由 M2.5 自主完成,覆盖研发、产品、销售、HR、财务等职能,且渗透率仍在持续上升。其中,在编程场景表现尤为突出,M2.5 生成的代码已占新提交代码的 80%。
编程:像架构师一样思考和构建
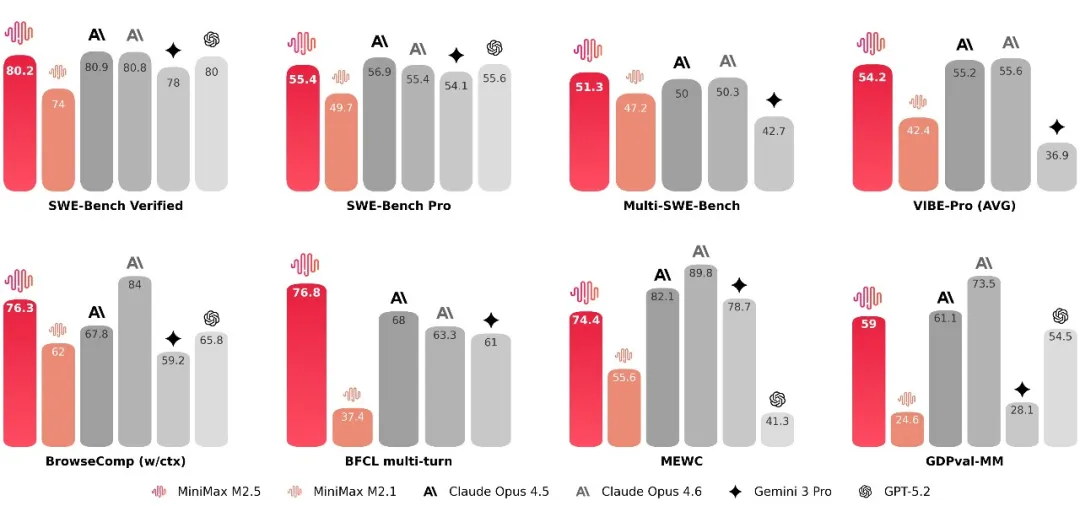
在编程的核心测试中,M2.5 相比于上一代模型有了显著提升,达到了跟 Claude Opus 系列类似的水平。在多语言相关的任务 Multi-SWE-Bench 上,M2.5 更是达到了第一。
M2.5 具备了「像架构师一样思考和构建」的能力,比如模型演化出了原生 Spec 行为:在动手写代码前,以架构师视角主动拆解功能、结构和 UI 设计,实现完整的前期规划。
M2.5 在超过 10 种语言(包括 GO、C、C++、TS、Rust、Kotlin、Python、Java、JS、PHP、Lua、Dart、Ruby)和数十万个真实环境中进行了训练。不仅限于 bug fixed 类场景,复杂系统的从 0-1 系统设计、环境构建,从 1-10 的系统开发,从 10-90 的功能迭代,从 90-100 的完备 code review 与系统测试,M2.5 都有可靠的表现,能够胜任各类复杂系统开发的全流程。
覆盖 Web、Android、iOS、Windows、Mac 等多平台的全栈项目,包含 Server 端 API、功能逻辑、DataBase 等,而不仅仅是“前端网页 demo”。
为了衡量相关能力,VIBE 基准升级为了更复杂、更具挑战性的 Pro 版:显著提升了任务复杂度、领域覆盖度和评估准确度。综合来看,M2.5 与 Opus4.5 表现相当。
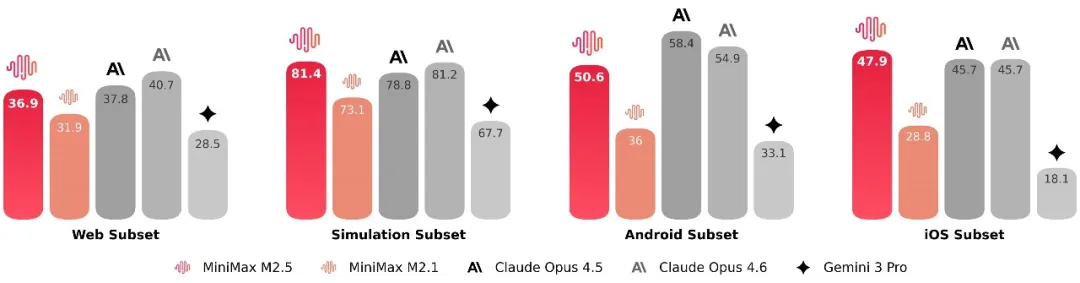
MiniMax关注了模型在不同脚手架上的泛化性,在不同的编程脚手架上测试了 SWE-Bench Verified 评测集上的表现。 在 Droid 上,M2.5 的通过率为 79.7,超过了 M2.1 的 71.3 分以及 Opus 4.6 的 78.9 分;在 OpenCode 上,M2.5 的通过率为 76.1, 超过了 M2.1 的 72.0 分和 Opus 4.6 的 75.9 分。
搜索和工具调用:更高效地解决问题
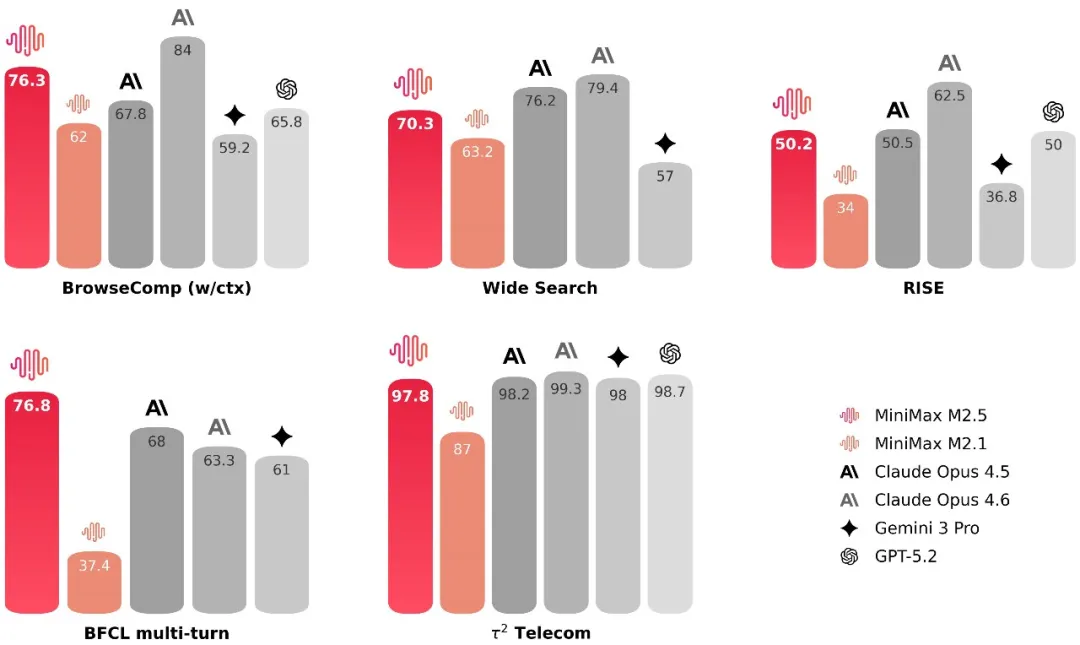
搜索和工具调用是模型能够自动处理复杂任务的前提,在 BrowseComp、Wide Search 等榜单的评测中,M2.5 在这些方面也达到了行业顶尖的水平。同时,模型的泛化能力也有提升。M2.5 在面对陌生的脚手架环境时,具有更加稳定的表现。
在人类专家真实的搜索任务中,使用搜索引擎只是一小部分,更多的是在专业网页内进行深度探索。为此MiniMax构建了 RISE(Realistic Interactive Search Evaluation),用于衡量模型在真实专业任务上的搜索能力。结果表明 M2.5 在真实世界的专家级搜索任务上表现卓越。
相比于前代模型,M2.5 在处理复杂任务时也展现出了更高的决策成熟度:它学会了用更精准的搜索轮次和更优的 token 效率去解决问题。例如,在 BrowseComp、Wide Search 和 RISE 多项任务中,M2.5 以更低的轮次消耗取得了更优的效果,相较于 M2.1 节省了大约 20% 的轮次消耗。这表明模型不再只是“做对”题目,而是能以更精简的路径逼近结果。
办公场景:直接交付专业产出
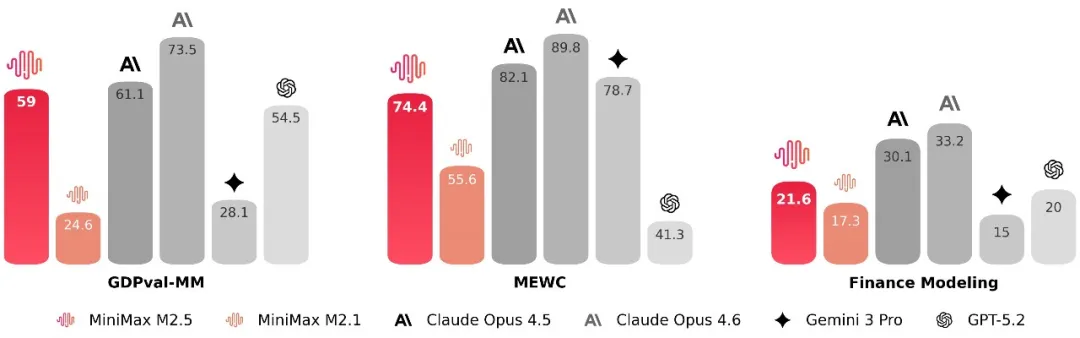
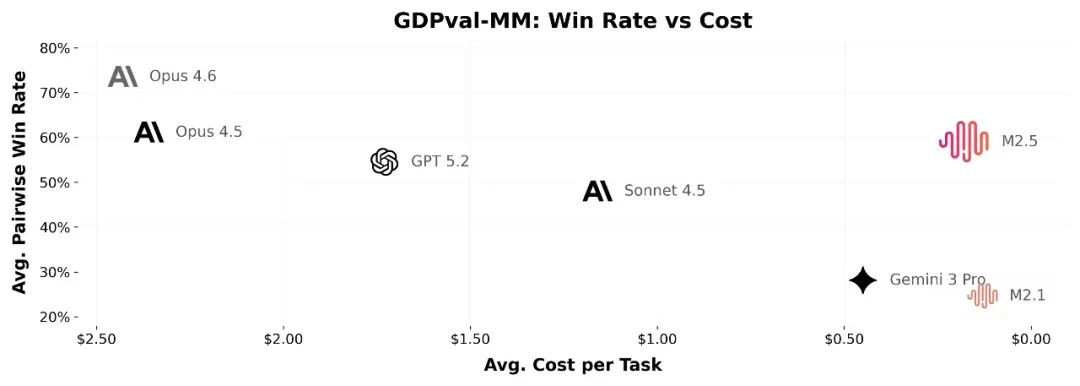
考虑在办公场景中,如何给出真正可交付的产物。为此,MiniMax与金融、法律、社会科学等领域的资深从业者展开深度合作,由他们提出需求、反馈问题、参与标准定义,并直接构建数据,将行业的隐性知识带入到模型的训练流程之中。在此基础上,M2.5 在 Word、PPT、Excel 金融建模等办公高阶场景中取得了显著的能力提升。在评测层面,构建了内部的 Cowork Agent 评测框架(GDPval-MM),以两两对比的方式评估模型的交付质量和轨迹的专业性,同时监控全流程的 token 费用,估算模型在生产力场景中的实际效益。在与主流模型的对比中,它取得了 59.0% 的平均胜率。
复杂任务快速推理
M2.5模型本来就提供 100 TPS 的推理速度,这几乎两倍于现在的主流模型。同时,在强化学习中注重优化了模型对复杂任务的拆解能力和思考过程的 token 消耗。这三个环节加在一起,使得 M2.5 在完成复杂任务的时间和成本上有显著的优势。
例如,在运行 SWE-Bench Verified 评测集时,M2.5 平均在每个任务上消耗了 3.52M 的 token。相比之下,M2.1 会消耗 3.72M tokens。同时,由于在并行工具调用等能力上的提升,端到端运行从平均 31.3 分钟减少到了 22.8 分钟,速度提升了 37%。这一耗时情况与 Claude Opus 4.6 的 22.9 分钟基本持平。
连续运行无成本负担
M2.5 提供两个效果一样,但是速度和价格不一样的版本:速度 100 TPS 左右的快速版本,处理每百万的 token 输入只需要 0.3 美金,处理每百万的 token 输出只需要 2.4 美金。而 50 TPS 的版本的输出价格还更低一倍。按照输出价格参考,50 TPS 的版本价格是 Opus、Gemini 3 Pro 以及 GPT5 这些模型的 1/10-1/20。
在以每秒输出 100 个 token 的情况下,连续工作一小时只需要 1 美金,而在每秒输出 50 个 token 的情况下,只需要 0.3 美金。也就是说,1 万美金可以让 4 个 Agent 连续工作一年。M2.5 提供了经济上几乎无限制地构建和运营 Agent 的可能性。对于 M2 系列的模型来说,唯一的问题变成了模型能力的进步速度。
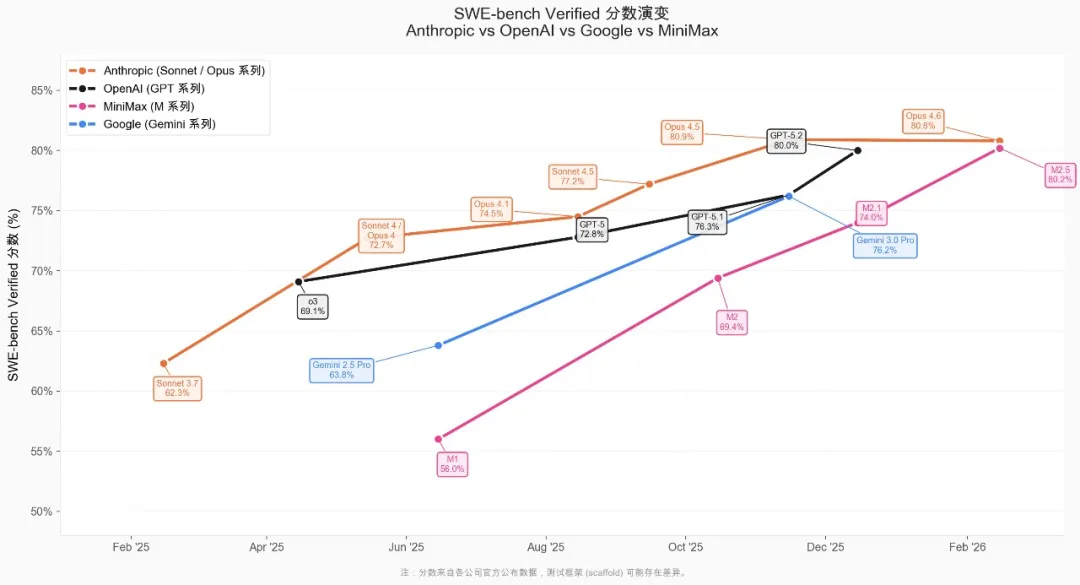
行业最快的进步速度
在编程领域最具代表性的 SWE-Bench Verfied 上面,相比 Claude、GPT 和 Gemini 等模型系列的进步速度,M2 系列模型保持了行业最快的进步速度。
原生 Agent RL 框架
大规模的强化学习显著地提升了模型能力以及对脚手架、环境的泛化性。通过 Agent RL 框架、算法和 Reward 设计、工程优化的 co-design, 支持对任意 Agent 脚手架与环境的高效优化,在包括大量公司内部真实任务的数十万个 Agent 脚手架与环境上大规模训练,验证了模型能力随算力和任务数的 scaling 取得近线性提升。
截至目前,用户已经在 MiniMax Agent 上构建了 1 万多个专家,且仍在快速增长。MiniMax 也针对办公、金融、编程等高频场景,在 MiniMax Agent 上构建了多组深度优化、开箱即用的专家套组。






