 超算云
超算云 AI智算云
AI智算云
 免费试算
免费试算 咨询客服
咨询客服
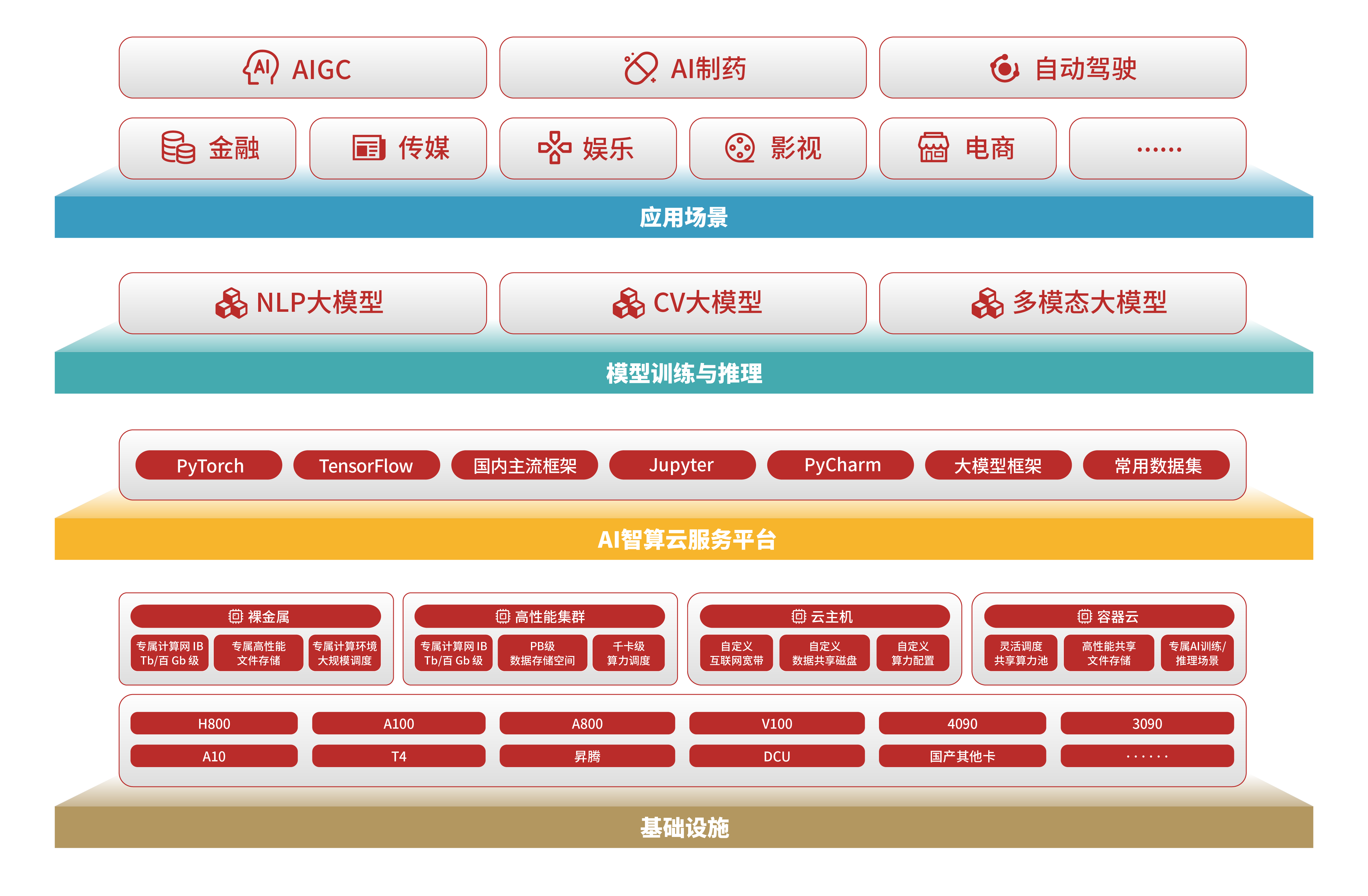
产品架构
面向生成式AI、自动驾驶、图像处理、科学计算和高性能计算等多种应用场景,打造的一款专业的、稳定的、高效的、易用的AI训练、推理一体化平台,并提供专业的、海量的基于超算架构的GPU算力云。
AI智算云通过裸金属、高性能集群、云主机和容器云等多种产品体系支撑,基于超算架构环境(IB高速互联)构建的GPU算力服务平台,满足大规模预训练、微调、高并发推理和高精度科学计算中对计算 、存储 、网络等环节的多样性需求 。通过资源汇聚、多云互联,融合“自营+互联”大规模算力资源池;通过多元化的合作模式,API Link链接使用场景,将深度为AI领域各行各业客户赋能;同时平台预置软件环境,开箱即用;专家团队7×24小时在线贴心服务,使科研工作者不为GPU算力分心,省时、省心,专注科研。
用户收益

省时
平台易用 开箱即用
提升科研效率
资源充裕 随需使用
保障科研成果及时产出

省心
专家团队7×24小时
在线支持
多元化服务保障
让科研更轻松

省钱
0建设与运维成本
按需租用
最小化拥有成本
平台优势
-

资源丰富
算力包括A800\A100\V100\3090\4090\A10\T4\国产DCU等多种型号,提供云主机、高性能集群等多种算力平台,支持多机多卡,满足训练、推理、科学计算等多计算场景需求。
-

易用高效
预装AI框架、内置数据集, 可通过简单直观的界面快速创建AI计算实例,高性能集群、独占显卡,性能强劲。
-

服务贴心
专家团队7×24小时在线服务,提供开发框架部署、算例编译、调试优化等,多元化服务支持,为AI客户深度赋能。
-

高性价比
建设与运维“0”成本,按需灵活选用海量资源,不操心管,只专注用。
应用场景
- 人工智能
- 高性能计算

人工智能
深度神经网络、特征抽取、图像分类、目标检测、语义分割、表示学习、生成对抗网络、语义网络、协同过滤和机器翻译等研究成为近年热点,相关技术已应用于计算机视觉、自然语言处理、语音处理及推荐系统等领域。AI智算云主机可灵活地满足相关人工智能技术研究,在训练和推理阶段对GPU算力复杂多样的需求。
 强劲算力
强劲算力单机提供NVIDIA Tesla最新架构8卡GPU,显卡直通,性能强劲,支持多机多卡并行提升算力。GPU卡型号丰富,满足训练和推理等多种场景需求。
 灵活配置
灵活配置自主选择GPU卡数、CPU核数、存储容量、网络带宽及操作系统类型等,可根据业务需求灵活构建。
 开箱即用
开箱即用预置TensorFlow、PyTorch、PyCharm、TensorBoard等框架环境,分钟级获得实例环境,即开即用。
 按需使用
按需使用支持按量、包月、包年等方式使用,起步“0”门槛。
常用环境
TensorFlow、PyTorch、Caffe、MXNet、Keras、PyCharm、Jupyter、OpenCV、TensorBoard、Python、CUDA、TensorRT、NCCL等。

高性能计算
在大规模多核计算场景中,GPU可大幅提高计算效率,使科研具有高出数量级的投入产出比,高性能程序GPU化趋势明显,GPU已广泛应用于生命科学、化学、材料、工业制造仿真设计、金融、气象海洋、油气能源等众多高性能计算领域。
 超强算力
超强算力提供NVIDIA Tesla最新架构GPU卡,以高性能集群输出,消除虚拟化性能损耗,输出极致的性能。
 高速互联
高速互联800Gb/s高速互连,高性能并行存储,支持大规模并行。
 弹性规模
弹性规模大规模集群架构及GPU队列资源池,可根据计算需求便捷获取数百卡计算资源。
常用软件
| 有限元分析:Abaqus、Ansys、OpenFOAM、 nanoFluidX等; | 生命科学:Blast、AlphaFold2等。 |
| 化学领域:Amber、Gromacs、 Lammps、Namd等; | 天气/环境建模:WRF、E3SM-EAM、COSMO等; |
典型案例

某985高校人工智能学院
某985高校人工智能学院
满足日常和紧急课题算力需求

中科院某研究所
中科院某研究所
保障按时完成基金课题研究

某自研大模型初创企业
某自研大模型初创企业
千张GPU卡,大模型高效训练

某新药研发企业
某新药研发企业
加速研发,项目时间缩短50%







