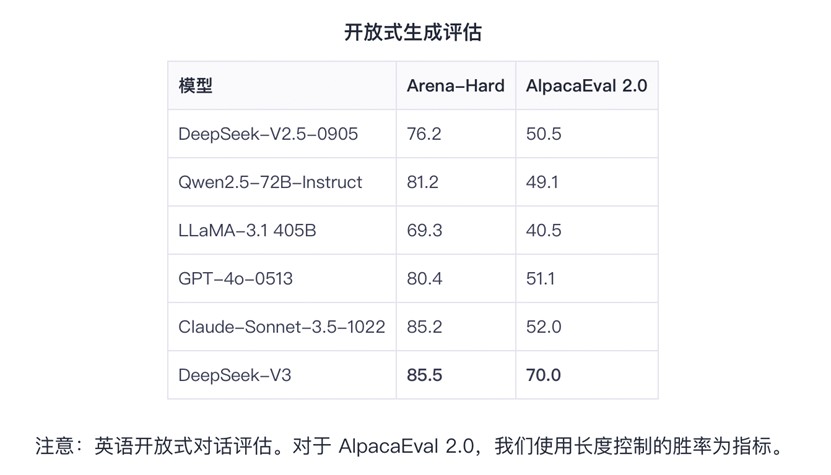
“当硅谷巨头依赖万卡集群烧钱训练时,中国团队用极低算力成本实现同OpenAI-o1媲美的模型——DeepSeek-R1,以算法突破将训练成本降至557.6万美元,登顶全球开源模型榜单。”
原来大模型训练,本不该如此昂贵。
开发者窘境
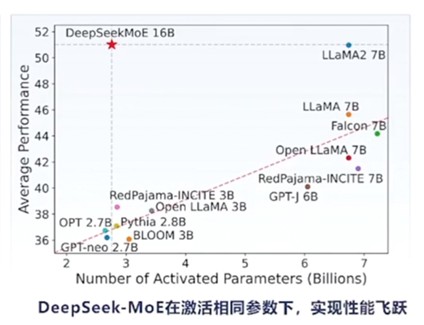
高昂的算力成本如同一道无形的枷锁,让许多中小型企业和个人开发者望而却步。例如,某初创公司曾计划开发一款图像识别应用,但面对A100显卡高昂的租赁费用,不得不放弃原方案。这不仅让创业团队步履维艰,也让创新变得艰难,许多有潜力的项目因成本高昂而被迫搁浅。如何打破这个困局?1、架构手术刀:DeepSeek-V3的混合专家架构(MoE)能够在不增加计算成本的情况下,拥有庞大的模型容量。 2、数据蒸馏术:DeepSeek-V3以其6710亿的参数规模成为当前最大的开源模型,但在实际应用中仅激活370亿参数,这大大降低了计算资源需求,提高了资源利用的效率。3、训练加速引擎:创新双向流水线设计,将训练任务划分为更小的计算块(chunk),并通过动态调度实现计算与通信重叠,使GPU利用率提升至95%以上,训练效率翻倍。
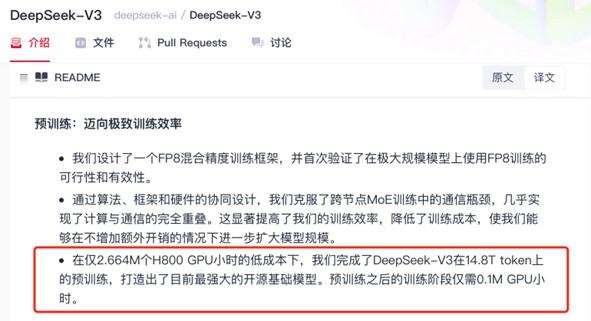
“在仅2.664M个H800 GPU小时的低成本下,我们完成了DeepSeek-V3在14.8T token上的预训练,打造出了目前最强大的开源基础模型。预训练之后的训练阶段仅需0.1M GPU小时。”DeepSeek的成功证明,大模型竞赛正在从“暴力美学”转向“精准外科手术”。
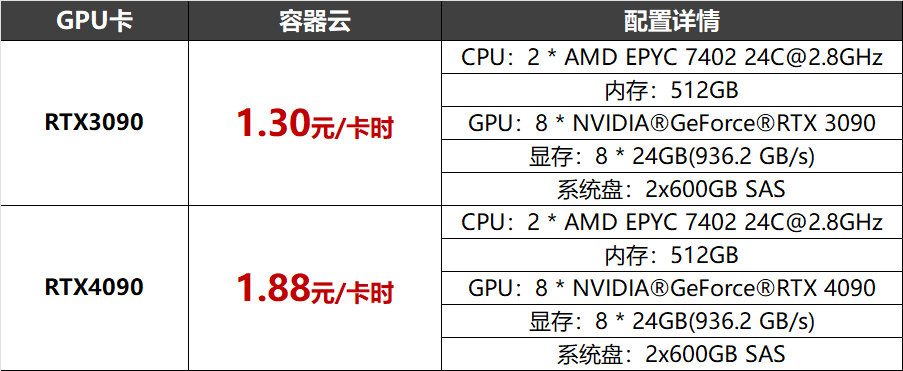
- 极速接入:DeepSeek-R1满血版(671B)模型已部署至北京超算AI智算云平台(ai.blsc.cn),支持快速部署,实现开箱即用;- 零配置启动:内置自动化分布式训练框架,分钟级创建预装DeepSeek的轻量化开发环境,零运维成本启动;H800/A100/A800/V100、RTX3090/4090、A10/T4,以及国产昇腾910等丰富资源,按需使用,智能调度,空闲资源灵活调用。计算网络采用1.6Tbps/3.2Tbps IB/RoCE无收敛架构,存储网络带宽达到400Gbps。新注册用户:注册即赠价值200元卡时 3090算力(可完成1亿参数模型全量训练);
企业用户:RTX 3090/4090最高可享单机8卡一周免费使用(约1344卡时),限云主机、容器云用户;
**写在最后**
DeepSeek用一己之力为中国的新一代AI技术开发撕开了一道裂缝,未来已来,北京超算将与中国AI事业一起推动算力成本革命!
 超算云
超算云 AI智算云
AI智算云